

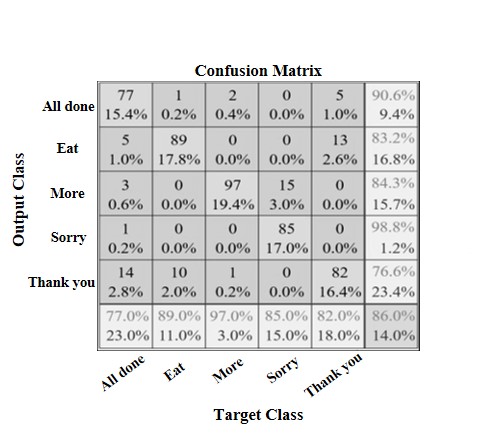
Accuracy Enhancement of Hand Gesture Recognition Using CNN
Human gestures are immensely significant in human-machine interactions. Complex hand gesture input and noise caused by the external environment must be addressed in order to improve the accuracy of hand gesture recognition algorithms. To overcome this challenge, we employ a combination of 2D-FFT and convolutional neural networks (CNN) in this research. The accuracy of human-machine interactions is improved by using Ultra Wide Bandwidth (UWB) radar to acquire image data, then transforming it with 2D-FFT and bringing it into CNN for classification. The classification results of the proposed method revealed that it required less time to learn than prominent models and had similar accuracy.
View this article on IEEE Xplore
Chat2VIS: Generating Data Visualizations via Natural Language Using ChatGPT, Codex and GPT-3 Large Language Models
The field of data visualisation has long aimed to devise solutions for generating visualisations directly from natural language text. Research in Natural Language Interfaces (NLIs) has contributed towards the development of such techniques. However, the implementation of workable NLIs has always been challenging due to the inherent ambiguity of natural language, as well as in consequence of unclear and poorly written user queries which pose problems for existing language models in discerning user intent. Instead of pursuing the usual path of developing new iterations of language models, this study uniquely proposes leveraging the advancements in pre-trained large language models (LLMs) such as ChatGPT and GPT-3 to convert free-form natural language directly into code for appropriate visualisations. This paper presents a novel system, Chat2VIS, which takes advantage of the capabilities of LLMs and demonstrates how, with effective prompt engineering, the complex problem of language understanding can be solved more efficiently, resulting in simpler and more accurate end-to-end solutions than prior approaches. Chat2VIS shows that LLMs together with the proposed prompts offer a reliable approach to rendering visualisations from natural language queries, even when queries are highly misspecified and underspecified. This solution also presents a significant reduction in costs for the development of NLI systems, while attaining greater visualisation inference abilities compared to traditional NLP approaches that use hand-crafted grammar rules and tailored models. This study also presents how LLM prompts can be constructed in a way that preserves data security and privacy while being generalisable to different datasets. This work compares the performance of GPT-3, Codex and ChatGPT across several case studies and contrasts the performances with prior studies.
View this article on IEEE Xplore
Security Hardening of Intelligent Reflecting Surfaces Against Adversarial Machine Learning Attacks
Next-generation communication networks, also known as NextG or 5G and beyond, are the future data transmission systems that aim to connect a large amount of Internet of Things (IoT) devices, systems, applications, and consumers at high-speed data transmission and low latency. Fortunately, NextG networks can achieve these goals with advanced telecommunication, computing, and Artificial Intelligence (AI) technologies in the last decades and support a wide range of new applications. Among advanced technologies, AI has a significant and unique contribution to achieving these goals for beamforming, channel estimation, and Intelligent Reflecting Surfaces (IRS) applications of 5G and beyond networks. However, the security threats and mitigation for AI-powered applications in NextG networks have not been investigated deeply in academia and industry due to being new and more complicated. This paper focuses on an AI-powered IRS implementation in NextG networks along with its vulnerability against adversarial machine learning attacks. This paper also proposes the defensive distillation mitigation method to defend and improve the robustness of the AI-powered IRS model, i.e., reduce the vulnerability. The results indicate that the defensive distillation mitigation method can significantly improve the robustness of AI-powered models and their performance under an adversarial attack.
View this article on IEEE Xplore
Tool Wear Monitoring Based on Transfer Learning and Improved Deep Residual Network
Considering the complex structure weight of the existing tool wear state monitoring model based on deep learning, prone to over-fitting and requiring a large amount of training data, a monitoring method based on Transfer Learning and Improved Deep Residual Network is proposed. First, the data is preprocessed, one-dimensional cutting force data are transformed into two-dimensional spectrum by wavelet transform. Then, the Improved Deep Residual Network is built and the residual module structure is optimized. The Dropout layer is introduced and the global average pooling technique is used instead of the fully connected layer. Finally, the Improved Deep Residual Network is used as the pre-training network model and the tool wear state monitoring model combined with the model-based Transfer Learning method is constructed. The results show that the accuracy of the proposed monitoring method is up to 99.74%. The presented network model has the advantages of simple structure, small number of parameters, good robustness and reliability. The ideal classification effect can be achieved with fewer iterations.
View this article on IEEE Xplore
On Online Adaptive Direct Data Driven Control
Based on our recent contributions on direct data driven control scheme, this paper continues to do some new research on direct data driven control, paving another way for latter future work on advanced control theory. Firstly, adaptive idea is combined with direct data driven control, one parameter adjustment mechanism is constructed to design the parameterized controller online. Secondly, to show the input-output property for the considered closed loop system, passive analysis is studied to be similar with stability. Thirdly, to validate whether the designed controller is better or not, another safety controller modular is added to achieve the designed or expected control input with the essence of model predictive control. Finally, one simulation example confirms our proposed theories. More generally, this paper studies not only the controller design and passive analysis, but also some online algorithm, such as recursive parameter identification and online subgradient descent algorithm. Furthermore, safety controller modular is firstly introduced in direct data driven control scheme.
View this article on IEEE Xplore
Dynamic Network Slice Scaling Assisted by Attention-Based Prediction in 5G Core Network
Network slicing is a key technology in fifth-generation (5G) networks that allows network operators to create multiple logical networks over a shared physical infrastructure to meet the requirements of diverse use cases. Among core functions to implement network slicing, resource management and scaling are difficult challenges. Network operators must ensure the Service Level Agreement (SLA) requirements for latency, bandwidth, resources, etc for each network slice while utilizing the limited resources efficiently, i.e., optimal resource assignment and dynamic resource scaling for each network slice. Existing resource scaling approaches can be classified into reactive and proactive types. The former makes a resource scaling decision when the resource usage of virtual network functions (VNFs) exceeds a predefined threshold, and the latter forecasts the future resource usage of VNFs in network slices by utilizing classical statistical models or deep learning models. However, both have a trade-off between assurance and efficiency. For instance, the lower threshold in the reactive approach or more marginal prediction in the proactive approach can meet the requirements more certainly, but it may cause unnecessary resource wastage. To overcome the trade-off, we first propose a novel and efficient proactive resource forecasting algorithm. The proposed algorithm introduces an attention-based encoder-decoder model for multivariate time series forecasting to achieve high short-term and long-term prediction accuracies. It helps network slices be scaled up and down effectively and reduces the costs of SLA violations and resource overprovisioning. Using the attention mechanism, the model attends to every hidden state of the sequential input at every time step to select the most important time steps affecting the prediction results. We also designed an automated resource configuration mechanism responsible for monitoring resources and automatically adding or removing VNF instances.
View this article on IEEE Xplore
A Novel Symmetric Stacked Autoencoder for Adversarial Domain Adaptation Under Variable Speed
At present, most of the fault diagnosis methods with extensive research and good diagnostic effect are based on the premise that the sample distribution is consistent. However, in reality, the sample distribution of rotating machinery is inconsistent due to variable working conditions, and most of the fault diagnosis algorithms have poor diagnostic effects or even invalid. To dispose the above problems, a novel symmetric stacked autoencoder (NSSAE) for adversarial domain adaptation is proposed. Firstly, the symmetric stacked autoencoder network with shared weights is used as the feature extractor to extract features which can better express the original signal. Secondly, adding domain discriminator that constituting adversarial with feature extractor to enhance the ability of feature extractor to extract domain invariant features, thus confusing the domain discriminator and making it unable to correctly distinguish the features of the two domains. Finally, to assist the adversarial training, the maximum mean discrepancy (MMD) is added to the last layer of the feature extractor to align the features of the two domains in the high-dimensional space. The experimental results show that, under the condition of variable speed, the NSSAE model can extract domain invariant features to achieve the transfer between domains, and the transfer diagnosis accuracy is high and the stability is strong.
*Published in the IEEE Reliability Society Section within IEEE Access.
View this article on IEEE Xplore
The Internet of Federated Things (IoFT)
The Internet of Things (IoT) is on the verge of a major paradigm shift. In the IoT system of the future, IoFT, the “cloud” will be substituted by the “crowd” where model training is brought to the edge, allowing IoT devices to collaboratively extract knowledge and build smart analytics/models while keeping their personal data stored locally. This paradigm shift was set into motion by the tremendous increase in computational power on IoT devices and the recent advances in decentralized and privacy-preserving model training, coined as federated learning (FL). This article provides a vision for IoFT and a systematic overview of current efforts towards realizing this vision. Specifically, we first introduce the defining characteristics of IoFT and discuss FL data-driven approaches, opportunities, and challenges that allow decentralized inference within three dimensions: (i) a global model that maximizes utility across all IoT devices, (ii) a personalized model that borrows strengths across all devices yet retains its own model, (iii) a meta-learning model that quickly adapts to new devices or learning tasks. We end by describing the vision and challenges of IoFT in reshaping different industries through the lens of domain experts. Those industries include manufacturing, transportation, energy, healthcare, quality & reliability, business, and computing.
View this article on IEEE Xplore
An In-Depth Study on Open-Set Camera Model Identification
Camera model identification refers to the problem of linking a picture to the camera model used to shoot it. In this paper, as this might be an enabling factor in different forensic applications to single out possible suspects (e.g., detecting the author of child abuse or terrorist propaganda material), many accurate camera model attribution methods have been developed. One of their main drawbacks, however, are a typical closed-set assumption of the problem. This means that an investigated photograph is always assigned to one camera model within a set of known ones present during the investigation, i.e., training time. The fact that a picture can come from a completely unrelated camera model during actual testing is usually ignored. Under realistic conditions, it is not possible to assume that every picture under analysis belongs to one of the available camera models. In this paper, to deal with this issue, we present an in-depth study on the possibility of solving the camera model identification problem in open-set scenarios. Given a photograph, we aim at detecting whether it comes from one of the known camera models of interest or from an unknown one. We compare different feature extraction algorithms and classifiers especially targeting open-set recognition. We also evaluate possible open-set training protocols that can be applied along with any open-set classifier, observing that a simple alternative among the selected ones obtains the best results. Thorough testing on independent datasets show that it is possible to leverage a recently proposed convolutional neural network as feature extractor paired with a properly trained open-set classifier aiming at solving the open-set camera model attribution problem even on small-scale image patches, improving over the state-of-the-art available solutions.
View this article on IEEE Xplore
Multi-Level Time-Sensitive Networking (TSN) Using the Data Distribution Services (DDS) for Synchronized Three-Phase Measurement Data Transfer
This paper presents the design and implementation of a Multi-level Time Sensitive Networking (TSN) protocol based on a real-time communication platform utilizing Data Distribution Service (DDS) middleware for data transfer of synchronous three phase measurement data. To transfer ultra-high three phase measurement samples, the DDS open-source protocol is exploited to shape the network’s data traffic according to specific Quality of Service (QoS) profiles, leading to low packet loss and low latency by synchronizing and prioritizing the data in the network. Meanwhile the TSN protocol enables time-synchronization of the measured data by providing a common time reference to all the measurement devices in the network, making the system less expensive, more secure and enabling time-synchronization where acquiring GPS signals is a challenge. A software library was developed and used as a central Quality of Service (QoS) profile for the TSN implementation. The proposed design and implemented real-time simulation prototype presented in this paper takes in consideration diverse scenarios at multiple levels of prioritization including publishers, subscribers, and data packets. This allows granular control and monitoring of the data for traffic shaping, scheduling, and prioritization. The major strength of this protocol lies in the fact that it’s not only in real time but it’s time-critical too. The simulation prototype implementation was performed using the Real Time Innovation (RTI) Connext connectivity framework, custom-built MATLAB classes and DDS Simulink blocks. Simulation results show that the proposed protocol achieves low latency and high throughput, which makes it a desired option for various communication systems involved in microgrids, smart cities, military applications and potentially other time-critical applications, where GPS signals become vulnerable and data transfer needs to be prioritized.
Follow us: