

Accuracy Enhancement of Hand Gesture Recognition Using CNN
Human gestures are immensely significant in human-machine interactions. Complex hand gesture input and noise caused by the external environment must be addressed in order to improve the accuracy of hand gesture recognition algorithms. To overcome this challenge, we employ a combination of 2D-FFT and convolutional neural networks (CNN) in this research. The accuracy of human-machine interactions is improved by using Ultra Wide Bandwidth (UWB) radar to acquire image data, then transforming it with 2D-FFT and bringing it into CNN for classification. The classification results of the proposed method revealed that it required less time to learn than prominent models and had similar accuracy.
View this article on IEEE Xplore
Novel Universal Power Electronic Interface for Integration of PV Modules and Battery Energy Storages in Residential DC Microgrids
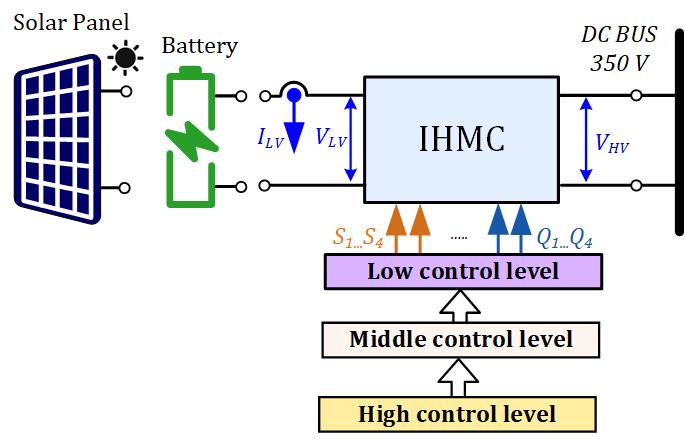
This paper introduces the novel concept of a highly versatile smart power electronic interface for fast deployment of residential dc microgrids. The proposed approach has bidirectional power flow control capabilities, wide operating voltage range, and high efficiency resulting from the topology morphing control utilization. This enables universal compatibility with the majority of the commercial 60- and 72-cell photovoltaic modules, as well as the efficient charge/discharge control of the 24 V and 48 V battery energy storages using the same hardware platform. The proposed concept features fully autonomous operation where switching between the photovoltaic and battery interfacing modes is automatically done using the input source identification algorithm. Moreover, the proposed universal interface converter employs droop control and solid-state protection, making it fully compatible with the emerging standards and requirements for power electronic systems used in dc microgrid environments. A 350 W prototype was developed and tested in the residential 350 V dc microgrid with droop control to validate the proposed concept experimentally.
View this article on IEEE Xplore
A Flexible Two-Tower Model for Item Cold-Start Recommendation
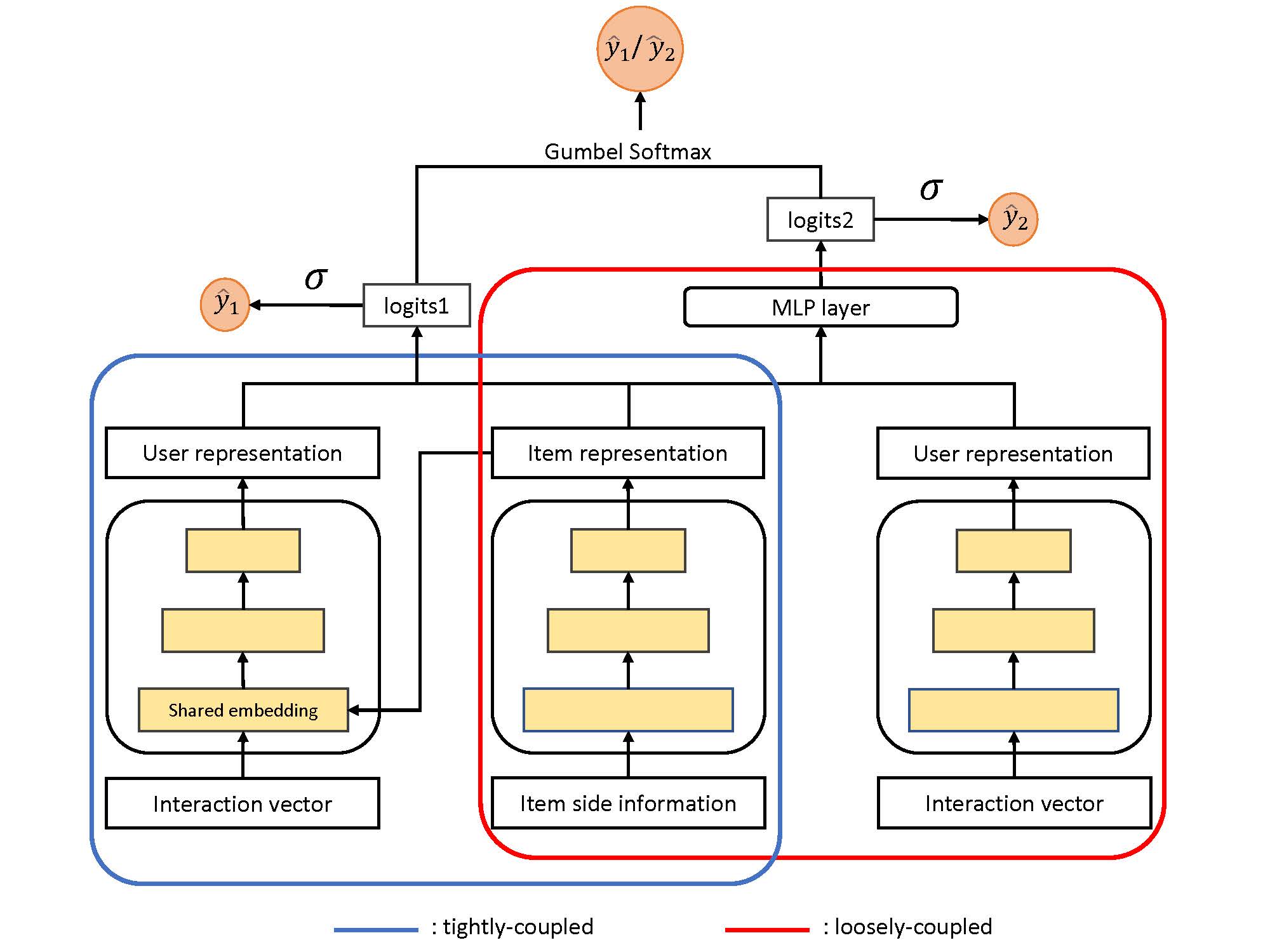
One of the main challenges in recommendation system is the item cold-start problem, where absence of historical interactions or ratings in new items makes recommendation difficult. In order to solve the cold-start problem, hybrid neural network models using meta data of the item as a feature is widely used. However, existing cold-start models tend to focus too much on utilizing the side information of items, which may not be flexible enough to capture the interaction information of users. In this study, we propose a flexible framework for better capturing the interaction information of users. Specifically, we incorporate the multiple choice learning scheme into the two-tower neural network which is a popular recommendation model that consists of two towers – one for users and one for items. In our proposed framework, we construct two encoders. One of the two encoders, the tightly-coupled encoder, focuses on the side information of items with which the user has interacted, the other one, loosely-coupled encoder, focuses the user’s interaction information. We utilize Gumbel-Softmax to stochastically select the encoder, enhancing the flexibility that considers not only item feature but also user interaction information. We evaluate our proposed framework on two datasets – the MLIMDb dataset which is a combination of widely used the MovieLens and IMDb datasets based on common movies, and the CiteULike dataset. The experimental results show that our proposed framework achieves state-of-the-art results on cold-start recommendation. In the Recall@150 experiments on the CiteULike dataset, we achieved improvement of approximately 2.7% compared to the base model. In the Recall@150 experiments on the MLIMDb dataset, we achieved improvement of approximately 5.2% compared to the base model. We further show our proposed model improves the performance in the warm-start settings. In the Recall@100 experiments on the Citeulike dataset, we observed an improvement of approximately 1.3% compared to the base model. In the Recall@100 experiments on the MLIMDb dataset, we observed an improvement of approximately 3.9% compared to the base model. Our proposed framework provides a flexible approach for capturing the diverse aspects of users in recommendation systems, even for cold-start items. As demonstrated through extensive experiments, our proposed model outperforms several State-Of-The-Art (SOTA) models on both datasets.
View this article on IEEE Xplore
A New Strategy for Combining Nonlinear Kalman Filters With Smooth Variable Structure Filters
Bayesian filters exemplified by the celebrated Kalman Filter (KF), and its non-linear variants rely on a fairly accurate state-space model of the system under study. To address the issue of modelling uncertainty in state estimation, the Smooth Variable Structure Filter (SVSF) was proposed in 2007. Since then, several SVSF variants have been proposed to extend its domain of applicability. In some of these algorithms, SVSF has been viewed as a complementary approach alongside the well-established nonlinear Kalman Filters. This paper seeks a general framework for SVSF formulation to unify some of the recent developments in SVSF literature under one umbrella. In this way, the SVSF variants are revisited as special cases of the proposed framework. This paper proposes a new strategy to combine SVSF filters with other nonlinear filters and puts existing SVSF filters under one umbrella. Six filters are formulated based on the proposed method of combining filters. The proposed filters relax limitations of existing SVSF variants, making the proposed filters more universal. In simulations, the new filters outperform state-of-the-art nonlinear KFs and some existing SVSF filters. To demonstrate the merits of the proposed framework, the new filters are applied to target tracking and are comparatively evaluated.
View this article on IEEE Xplore
RL-Based Cache Replacement: A Modern Interpretation of Belady’s Algorithm With Bypass Mechanism and Access Type Analysis
Belady’s algorithm is widely known as an optimal cache replacement policy. It has been the foundation of numerous recent studies on cache replacement policies, and most studies assume this as an upper limit. Despite its widespread adoption, we discovered opportunities to unleash the headroom by addressing cache access types and implementing cache bypass. In this study, we propose Stormbird, a cache replacement policy that synergistically integrates the extensions of Belady’s algorithm and the power of reinforcement learning. Reinforcement learning is well-suited for cache replacement policy problems owing to its ability to interact dynamically with the environment, adapt to changing access patterns, and optimize the maximum cumulative rewards. Stormbird utilizes several selected features from the reinforcement learning model to enhance the instructions per cycle efficiency while maintaining a low hardware area overhead. Furthermore, it considers cache access types and integrates dynamic set dueling techniques to improve the cache performance. For 2 MB last-level cache per core, Stormbird achieves an average instructions per cycle improvement of 0.13% over the previous state-of-the-art on a single-core system and 0.02% on a four-core system while simultaneously reducing hardware overhead by 62.5%. Stormbird incurs a low hardware overhead of only 10.5 KB for 2 MB last-level cache and can be implemented without using program counter values.
View this article on IEEE Xplore
Exploring Students’ Perceptions of ChatGPT: Thematic Analysis and Follow-Up Survey
ChatGPT has sparked both excitement and skepticism in education. To analyze its impact on teaching and learning it is crucial to understand how students perceive ChatGPT and assess its potential and challenges. Toward this, we conducted a two-stage study with senior students in a computer engineering program ( n=56 ). In the first stage, we asked the students to evaluate ChatGPT using their own words after they used it to complete one learning activity. The returned responses (3136 words) were analyzed by coding and theme building (36 codes and 15 themes). In the second stage, we used the derived codes and themes to create a 27-item questionnaire. The students responded to this questionnaire three weeks later after completing other activities with the help of ChatGPT. The results show that the students admire the capabilities of ChatGPT and find it interesting, motivating, and helpful for study and work. They find it easy to use and appreciate its human-like interface that provides well-structured responses and good explanations. However, many students feel that ChatGPT’s answers are not always accurate and most of them believe that it requires good background knowledge to work with since it does not replace human intelligence. So, most students think that ChatGPT needs to be improved but are optimistic that this will happen soon. When it comes to the negative impact of ChatGPT on learning, academic integrity, jobs, and life, the students are divided. We conclude that ChatGPT can and should be used for learning. However, students should be aware of its limitations. Educators should try using ChatGPT and guide students on effective prompting techniques and how to assess generated responses. The developers should improve their models to enhance the accuracy of given answers. The study provides insights into the capabilities and limitations of ChatGPT in education and informs future research and development.
View this article on IEEE Xplore
Published in the IEEE Education Society Section
Efficiency Optimization Design That Considers Control of Interior Permanent Magnet Synchronous Motors Based on Machine Learning for Automotive Application
Interior permanent magnet synchronous motors have become widely used as traction motors in environmentally friendly vehicles. Interior permanent magnet synchronous motors have a high degree of design freedom and time-consuming finite element analysis is required for their characteristics analysis, which results in a long design period. Here, we propose a method for fast efficiency maximization design that uses a machine-learning-based surrogate model. The surrogate model predicts motor parameters and iron loss with the same accuracy as that of finite element analysis but in a much shorter time. Furthermore, using the current and speed conditions in addition to geometry information as input to the surrogate model enables design optimization that considers motor control. The proposed method completed multi-objective multi-constraint optimization for multi-dimensional geometric parameters, which is prohibitively time-consuming using finite element analysis, in a few hours. The proposed shapes reduced losses under a vehicle test cycle compared with the initial shape. The proposed method was applied to motors with three rotor topologies to verify its generality.
View this article on IEEE Xplore
Published in the IEEE Vehicular Technology Society Section
Deep Embedded Clustering Framework for Mixed Data
Deep embedded clustering (DEC) is a representative clustering algorithm that leverages deep-learning frameworks. DEC jointly learns low-dimensional feature representations and optimizes the clustering goals but only works with numerical data. However, in practice, the real-world data to be clustered includes not only numerical features but also categorical features that DEC cannot handle. In addition, if the difference between the soft assignment and target values is large, DEC applications may suffer from convergence problems. In this study, to overcome these limitations, we propose a deep embedded clustering framework that can utilize mixed data to increase the convergence stability using soft-target updates; a concept that is borrowed from an improved deep Q learning algorithm used in reinforcement learning. To evaluate the performance of the framework, we utilized various benchmark datasets composed of mixed data and empirically demonstrated that our approach outperformed existing clustering algorithms in most standard metrics. To the best of our knowledge, we state that our work achieved state-of-the-art performance among its contemporaries in this field.
View this article on IEEE Xplore
Chat2VIS: Generating Data Visualizations via Natural Language Using ChatGPT, Codex and GPT-3 Large Language Models
The field of data visualisation has long aimed to devise solutions for generating visualisations directly from natural language text. Research in Natural Language Interfaces (NLIs) has contributed towards the development of such techniques. However, the implementation of workable NLIs has always been challenging due to the inherent ambiguity of natural language, as well as in consequence of unclear and poorly written user queries which pose problems for existing language models in discerning user intent. Instead of pursuing the usual path of developing new iterations of language models, this study uniquely proposes leveraging the advancements in pre-trained large language models (LLMs) such as ChatGPT and GPT-3 to convert free-form natural language directly into code for appropriate visualisations. This paper presents a novel system, Chat2VIS, which takes advantage of the capabilities of LLMs and demonstrates how, with effective prompt engineering, the complex problem of language understanding can be solved more efficiently, resulting in simpler and more accurate end-to-end solutions than prior approaches. Chat2VIS shows that LLMs together with the proposed prompts offer a reliable approach to rendering visualisations from natural language queries, even when queries are highly misspecified and underspecified. This solution also presents a significant reduction in costs for the development of NLI systems, while attaining greater visualisation inference abilities compared to traditional NLP approaches that use hand-crafted grammar rules and tailored models. This study also presents how LLM prompts can be constructed in a way that preserves data security and privacy while being generalisable to different datasets. This work compares the performance of GPT-3, Codex and ChatGPT across several case studies and contrasts the performances with prior studies.
View this article on IEEE Xplore
Nanoflowers Versus Magnetosomes: Comparison Between Two Promising Candidates for Magnetic Hyperthermia Therapy
Magnetic Fluid Hyperthermia mediated by iron oxide nanoparticles is one of the most promising therapies for cancer treatment. Among the different candidates, magnetite and maghemite nanoparticles have revealed to be some of the most promising candidates due to both their performance and their biocompatibility. Nonetheless, up to date, the literature comparing the heating efficiency of magnetite and maghemite nanoparticles of similar size is scarce. To fill this gap, here we provide a comparison between commercial Synomag Nanoflowers (pure maghemite) and bacterial magnetosomes (pure magnetite) synthesized by the magnetotactic bacterium Magnetospirillum gryphiswaldense of ⟨D⟩≈ 40 –45 nm. Both types of nanoparticles exhibit a high degree of crystallinity and an excellent degree of chemical purity and stability. The structural and magnetic properties in both nanoparticle ensembles have been studied by means of X–Ray Diffraction, Transmission Electron Microscopy, X–Ray Absorption Spectroscopy, and SQUID magnetometry. The heating efficiency has been analyzed in both systems using AC magnetometry at several field amplitudes (0–88 mT) and frequencies (130, 300, and 530 kHz).
View this article on IEEE Xplore
Published in the IEEE Magnetics Society Section.
Follow us: